面试题一览
- 介绍hiberante
Hibernate是一个基于Java的开源的持久化中间件,对JDBC做了轻量的封装。
采用ORM(object relational mapping)对象-关系映射机制,负责实现Java对象和关系数据库之间的映射,hibernate可以自动生成SQL语句,并且把数据库返回的结果封装成对象。内部封装了JDBC访问数据库的操作,向上层应用提供了面向对象的数据库访问API.
优点:以对象的形式操作数据,提高开发效率,不用关心数据库种类(换数据库只要修改配值文件)。
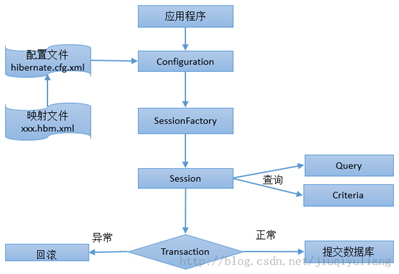
- Hibernate的执行流程
- 通过Configuration().configure();读取并解析hibernate.cfg.xml配置文件。
- 由hibernate.cfg.xml中的
读取解析映射信息。
- 通过config.buildSessionFactory();//得到sessionFactory。
- sessionFactory.openSession();//得到session。
- session.beginTransaction();//开启事务。
- persistent operate;
- session.getTransaction().commit();//提交事务
- 关闭session;
- 关闭sessionFactory;
- JDBC,Hibernate 分页怎样实现?
- Hibernate 的分页:
Query query = session.createQuery(”from Student”);
query.setFirstResult(firstResult);//设置每页开始的记录号
query.setMaxResults(resultNumber);//设置每页显示的记录数
Collection students = query.list();
- JDBC 的分页:根据不同的数据库采用不同的sql 分页语句
例如: Oracle 中的sql 语句为: “SELECT * FROM (SELECT a.*, rownum r FROM TB_STUDENT) WHERE r between 2 and 10″ 查询从记录号2 到记录号10 之间的所有记录。
- hibernate中离线查询去除重复项怎么加条件?
dc.setResultTransformer(Criteria.DISTINCT_ROOT_ENTITY);
- hibernate用get 和load方法 这2个方法来查没有的数据 那么分别会反馈什么样的结果?
get返回null,load classnotfoundException
- Hibernate中离线查询与在线查询的区别
Criteria 和 DetachedCriteria 的主要区别在于创建的形式不一样, Criteria 是在线的,所以它是由 Hibernate Session 进行创建的;而 DetachedCriteria 是离线的,创建时无需 Session,DetachedCriteria 提供了 2 个静态方法 forClass(Class) 或 forEntityName(Name) 进行DetachedCriteria 实例的创建。
- Hibernate 的初始化.
读取Hibernate 的配置信息-〉创建Session Factory
1)创建Configeration类的实例。
它的构造方法:将配置信息(Hibernate config.xml)读入到内存。
一个Configeration 实例代表Hibernate 所有Java类到Sql数据库映射的集合。
2)创建SessionFactory实例
把Configeration 对象中的所有配置信息拷贝到SessionFactory的缓存中。
SessionFactory的实例代表一个数据库存储员源,创建后不再与Configeration 对象关联。
缓存(cache):指Java对象的属性(通常是一些集合类型的属性--占用内存空间。
- hibernate的save与saveOrUpdate的区别?get与load的区别?
答案: Transient状态–离线状态,Persient状态–持久状态,Detached状态–脱管状态
1.save()方法,调用save方法时,首先会在session缓存中查找保存对象如果实体对象已经处于Persient状态,直接返回,否在实行sql操作,并将保存的实体对象加入session缓存(save方法不会把实体加入二级缓存的),最后对存在的级联关系进行递归处理。
2.saveOrUpdate()方法:和save方法一样首先在session缓存中查找,判断对象是否为为保存状态,如果对象处于Persient,不执行操作,处于Transient执行save操作,处于Detached调用save将对象与session重新关联(简单的说就是该方法会先看该对象是否已经存在,如果已经存在就更新,否则新增保存)。
3.get与load的区别?load会先从缓存中查询,如果不存在再到数据库查询;而get是直接从数据库中查询;load的效率会快点(因为他从缓存中查询)
- Hibernate 中的HQL和 criteria的区别?
1.QBC(Query by Criteria)查询对查询条件进行了面向对象封装,符合编程人员的思维方式;
2.HQL(Hibernate Query Language)查询提供了更加丰富的和灵活的查询特性,在涵盖Criteria查询的所有功能的前提下,提供了类似标准SQL语句的查询方式,同时也提供了更加面向对象的封装;
-
Hibernate有哪几种查询数据的方法?
答:hibernate在查询方式上有三种方式:HQL SQL QBC
-
Hrbernate的二级缓存讲述。
hibernate的session提供了一级缓存,每个session,对同一个id进行两次load,不会发送两条sql给数据库,但是session关闭的时候,一级缓存就失效了。
二级缓存是SessionFactory级别的全局缓存,它底下可以使用不同的缓存类库,比如ehcache、oscache等。hibernate在执行任何一次查询的之后,都会把得到的结果集放到缓存中,缓存结构可以看作是一个hash table,key是数据库记录的id,value是id对应的pojo对象。当用户根据id查询对象的时候(load、iterator方法),会首先在缓存中查找,如果没有找到再发起数据库查询。
第一章-Hibernate概述
1什么是Hibernate
object relational mapping
Hibernate是一个基于Java的开源的持久化中间件,对JDBC做了轻量的封装。
采用ORM(object relational mapping)对象-关系映射机制,负责实现Java对象和关系数据库之间的映射,hibernate可以自动生成SQL语句,并且把数据库返回的结果封装成对象。内部封装了JDBC访问数据库的操作,向上层应用提供了面向对象的数据库访问API.
优点:以对象的形式操作数据,提高开发效率,不用关心数据库种类(换数据库只要修改配值文件)。
- 掌握Hiberate的基本配置——即搭建Hiberate开发环境
- 掌握Hiberate常用API——即如何使用Hiberate框架进行开发
- 掌握Hiberate的关联映射——解决表与表之间存在的关系问题,有1:n(一对多)、 1:1(一对一)、m:n(多对多)关系
- 掌握Hiberate的检索方式——即掌握Hiberate的查询
- 掌握Hiberate的优化方式——即提高Hiberate的效率
1.1配置hibernate
在Spring中配置hibernate,注意不同的dataSource的class,所要注入的属性名称不同。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
|
<?xml version="1.0" encoding="UTF-8"?>
<beans
xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:p="http://www.springframework.org/schema/p"
xmlns:tx="http://www.springframework.org/schema/tx"
xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.0.xsd
http://www.springframework.org/schema/tx
http://www.springframework.org/schema/tx/spring-tx-3.0.xsd
http://www.springframework.org/schema/aop
http://www.springframework.org/schema/aop/spring-aop-3.0.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-3.0.xsd
">
<!--mysql数据库的配置
<bean id="dataSource"
class="org.springframework.jdbc.datasource.DriverManagerDataSource">
<property name="driverClassName" value="${jdbc.driver}"/>
<property name="url" value="${jdbc.url}"/>
<property name="username" value="${jdbc.username}"/>
<property name="password" value="${jdbc.password}"/>
</bean>
-->
<!--Oracle数据库的配置 -->
<bean id="dataSource"
class="org.springframework.jdbc.datasource.DriverManagerDataSource">
<property name="driverClassName" value="oracle.jdbc.driver.OracleDriver"></property>
<property name="url"
value="jdbc:oracle:thin:@localhost:1521:orcl">
</property>
<property name="username" value="scott"></property>
<property name="password" value="tiger"></property>
</bean>
<bean id="sessionFactory"
class="org.springframework.orm.hibernate5.LocalSessionFactoryBean">
<property name="dataSource"><ref bean="dataSource" /></property>
<property name="hibernateProperties">
<props>
<!--MySql数据库方言 org.hibernate.dialect.MySQLDialect -->
<prop key="hibernate.dialect">org.hibernate.dialect.Oracle10gDialect</prop>
<prop key="hibernate.show_sql">true</prop> <!--控制台打印sql-->
<prop key="hibernate.format_sql">true</prop> <!--打印sql格式转换-->
</props>
</property>
<property name="packagesToScan"> <!--扫描关系映射-->
<list><value>com.lx.vo</value></list>
</property>
</bean>
<!-- 启用注解扫描 -->
<context:component-scan base-package="com.lx.controller" />
<context:component-scan base-package="com.lx.impl" />
<!-- 1创建事务管理器 -->
<bean id="transactionManager" class="org.springframework.orm.hibernate5.HibernateTransactionManager">
<property name="sessionFactory" ref="sessionFactory"></property>
</bean>
<!-- 开启事务注解驱动 -->
<tx:annotation-driven transaction-manager="transactionManager" proxy-target-class="true"/>
</beans>
|
1.2注解设置实体类
相关网址:网址一 网址二
1表、主键相关的注解
注意让Spring扫描
1
2
3
4
5
6
7
8
9
10
11
|
@Entity //表示为实体类 导入都是此包下的import javax.persistence.*
@Table(name="users") //设置数据库中的表名
public class Users {
//这里使用的数据库是Oracle使用了序列,所以要声明一个序列SequenceGenerator,再设置一个别名,可以引用它
//allocationSize表示每次增长的长度。
@SequenceGenerator(name="seq_users",sequenceName="seq_users" ,allocationSize=1)
@Id //id表示是数据库的主键 strategy表示引用的@SequenceGenerator的名称
@GeneratedValue(strategy = GenerationType.SEQUENCE,generator = "seq_users")
private Integer users_id ;
//用来限制列名,列唯一,列为null
@Column(name = "id", unique = true, nullable = false)
|
@GeneratedValue将指定主键值的来源,其属性strategy用于指定主键的生成策略。其值为系统定义好的四种策略之一。默认为AUTO。@GeneratedValue(strategy = GenerationType.SEQUENCE)
GenerationType取值有四种:
- AUTO,INDENTITY,SEQUENCE 和 TABLE 4种
上面是Oracle的例子,下面介绍MySql的(id自动增长)
-
1
2
|
@Id
@GeneratedValue(strategy=GenerationType.IDENTITY)
|
import com.fasterxml.jackson.annotation.JsonIgnore;
@JsonIgnore注解
用于springmvc返回json数据时,忽略该字段。
1.3写基础类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
|
package com.lx.impl;
import org.hibernate.SessionFactory;
import org.hibernate.query.Query;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Repository;
import org.springframework.transaction.annotation.Transactional;
import java.util.List;
@Transactional //因为有事务,所以可以不再开启事务。
@Repository
public class BaseDaoImpl {
@Autowired
private SessionFactory sessionFactory;
//获得currentSession
public Session getCurrentSession() {
return sessionFactory.getCurrentSession();
}
//删除
public void delete(Object obj) {
sessionFactory.getCurrentSession().delete(obj);
}
//添加
public void save(Object obj) {
sessionFactory.getCurrentSession().save(obj);
}
//通过hql查询
public List selectManyByHql(String hql) {
return sessionFactory.getCurrentSession().createQuery(hql).list();
}
//修改
public void update(Object obj) {
sessionFactory.getCurrentSession().update(obj);
}
//通过Id查找一条
public Object selectOneById(Class cls, Integer id) {
return sessionFactory.getCurrentSession().get(cls, id);
}
//通过hql查询一条
public Object selectOneByHql(String hql) {
return sessionFactory.getCurrentSession().createQuery(hql).uniqueResult();
}
//实现分页
public List selectByPage( String hql, Integer current, Integer pageSize){
Query query=sessionFactory.getCurrentSession().createQuery(hql);
query.setFirstResult(current);
query.setMaxResults(pageSize);
return query.getResultList();
}
//统计所有数据条数
public Integer selectTotalCount( String hql){
Query query=sessionFactory.getCurrentSession().createQuery(hql);
Long count=(Long) query.uniqueResult();
return count.intValue();
}
public SessionFactory getSessionFactory() {
return sessionFactory;
}
}
|
2基于注解的关系
2.1一对一的关系
1
2
3
4
|
//一个短消息,对应一个发送人
@OneToOne(fetch=FetchType.LAZY,optional=false)
@JoinColumn(name="creator",insertable = false,updatable = false)
private ZzEmployee employee;
|
insertable = false,updatable = false,级联插入和修改–否。
optional=false插入时字段,可否为null,fase不可以。
2.2一对多的关系
集合最好使用,set,HashSet否则无法同时抓取多个。
一对多://一个短消息,对应多个消息接收
1
2
3
|
@OneToMany(cascade=CascadeType.ALL,fetch=FetchType.LAZY)
@JoinColumn(name="xiaoxiid")
private List<XxXiaoxijieshou> receive=new ArrayList<XxXiaoxijieshou>();
|
//多对一,一个消息接收,对应一个消息发送人
1
2
3
|
@ManyToOne(targetEntity=XxDuanxiaoxi.class,fetch=FetchType.LAZY)
@JoinColumn(name="xiaoxiid",insertable=false,updatable=false)
private XxDuanxiaoxi shortInfo;
|
2.3多对多的关系
1
2
3
4
5
6
7
8
9
|
//角色 员工多对多
//连接第三张表为qx_role_user,没有主键,
//@JoinColumn第三表中,本bean存储的字段为
//inverseJoinColumns第三表中,连接员工bean存储的字段为
@ManyToMany()
@JoinTable(name="qx_role_user",
joinColumns= {@JoinColumn(name="roleid")},
inverseJoinColumns= {@JoinColumn(name="eid")})
private Set<ZzEmployee> emps=new HashSet<ZzEmployee>();
|
2.4一对多自联
自联结教程https://blog.csdn.net/baidu_28283827/article/details/52789151
1
2
3
4
5
6
7
|
//自关联 一对多,一个父亲功能下,有多个子功能
//parentoid为自身bean的Id
@OneToMany(fetch=FetchType.LAZY,
cascade=CascadeType.ALL,
orphanRemoval=true)
@JoinColumn(name="parentoid",insertable=false,updatable=true)
private List<QxFunction> children=new ArrayList<QxFunction>();
|
3关键字的介绍
==cascade==/kæˈskeɪd/小瀑布,瀑布状物;串联
cascade="all">默认为none不进行关联,save-update保存或修改关联,为all是增删改都关联。
(未验证)常常和inverse="false"连用?
1
2
3
4
5
|
cascade表示级联操作
CascadeType.MERGE级联更新:若items属性修改了那么order对象保存时同时修改items里的对象。对应EntityManager的merge方法
CascadeType.REFRESH级联刷新:获取order对象里也同时也重新获取最新的items时的对象。对应EntityManager的refresh(object)方法有效。即会重新查询数据库里的最新数据
CascadeType.PERSIST级联保存:对order对象保存时也对items里的对象也会保存。对应EntityManager的presist方法
CascadeType.REMOVE级联删除:对order对象删除也对items里的对象也会删除。对应EntityManager的remove方法
|
==inverse==/ˌɪnˈvɜːrs/ 相反的;倒转的,关系维护交给对方吗。
=false为主动维护关系,=true意思是放弃维护关系,交给对方维护。
注意:
默认为:inverse=false维护关系
inverse只存在于集合标记的元素中 。既只在many-to-many中,one-to-many
Hibernate提供的集合元素包括<set/> <map/> <list/> <array /> <bag />
例子:
1
2
3
4
5
6
7
8
9
10
11
12
|
单向one-to-many关联关系中,不可以设置inverse="true",因为被控方的映射文件中没有主控方的信息。**
一对多关系时候,department部门表可以通过自己主键,去staff找did=x的员工。**
inverse=false,维护关系
save时候,1会先保存员工,2保存experience经历,3为经历设置外键
inverse=true,放弃维护关系
save时候,1会先保存员工,2保存experience经历,
若无many-to-one关系,则无法维护关系,experience不会设置staffId
inverse=true时候,放弃维护关系,
保存部门时,部门的staffs若有员工,员工会保存到数据库,但员工中没有部门Id,因为此时部门放弃维护关系。
|
==lazy==
lazy=true懒加载,一对一为立即加载。
==optional=false== 是否允许该字段为null,限制插入时字段。
optional:是否允许该字段为null,该属性应该根据数据库表的外键约束来确定,默认为true
optional属性是定义该关联类是否必须存在,
值为false 时,关联类双方都必须存在,如果关系被维护端不存在,查询的结果为null。
值为true 时, 关系被维护端可以不存在,查询的结果仍然会返回关系维护端,在关系维护端中指向关系被维护端的属性为null。
4常见错误
should be mapped with insert="false” update="false”
原因:在建立对象之间的关系的时候定义了外键,又在属性中重复设置了。
@JoinColumn(name="accountid”)建立对象关系,又在属性中设置了accountid。
解决办法是,查询时候,先抓取accountid然后,给这个集合取别名,然后别名.oid进行判断。
第二章-hql语句
1查询方式
1.0返回值问题
1
2
3
|
Object obj=query.uniqueResult();//不存在 会返回为null
List obj=query.list();//list 即使size=0也不会返回为null
//在含有一对多集合的关系中,即使抓取的集合为0,集合也不是==null
|
1.1实例化查询
在testDeotBean中要有该查询的构造方法,也要有无参构造方法
查询多个数据 select new testdeptBean(did,dname) from testdeptBean "
注意,实例化查询无法用于join fetch
对象导航查询:testdeptBean dept=session.get(testdeptBean.class, 26); 不常用
1.2连接查询fetch
连接查询-统计条数:select count(s) from Staff s left join s.account a
连接查询-查找数据:session.createQuery(“from Department dept left join fetch dept.employees” 会把department中的employee抓取出来
注意left join fetch会产生重复数据 需要 select distinct(对象)
1.3聚合函数
1
2
3
4
5
6
7
8
9
|
Query query=session.createQuery("select avg(did) from testdeptBean");
Object obj=query.uniqueResult(); //可以直接获得结果不需要遍历
COUNT 返回Long对象
MAX MIN 返回类型是跟所使用的字段类型有关
AVG 返回Double
SUM 如使用字段是整形,返回Long,若字浮点,返回浮点
//是Long时 可以这样处理。
Long obj=(Long)obj1;
Integer in=obj.intValue();
|
1.4分页实现
1
2
3
4
|
//设置开始位置 从0开始 显示两条数据
query.setFirstResult(2);
//设置每页记录数
query.setMaxResults(2);
|
1.5条件查询
hibernate5之后,条件查询的限定需要在?后加数字。
模糊查询:from 实体类名 where 属性=? and 属性 like :name
query.setParameter("biaoti", "%"+biaoti+"%");
方式一:加数字,避免sql注入
1
2
3
|
Query query=session.createQuery(
"select new Users(users_name) from Users where users_name=?1");
query.setParameter(1,users_name);
|
方式二:起别名,(setString等已过时,使用setParameter)
1
2
3
4
5
6
7
|
//别名:要求必须以冒号开头: list.setParameter()/setInteger也可以
String hql = "from Student where age > :myage and score < :myscore";
Query createQuery = session.createQuery(hql);
List<Student> list = createQuery
.setParameter("myage", 21)
.setParameter("myscore", 95)
.list();
|
1.6子查询
1
2
3
|
//操作集合:查找经历等于二的员工size: from Staff s where s.experiences.size=2
//子查询:查找经历大于1的: from Staff s where 1<(select count(e) from s.experiences e)
//in:与”=any”等价:表示子查询语句返回的所有记录
|